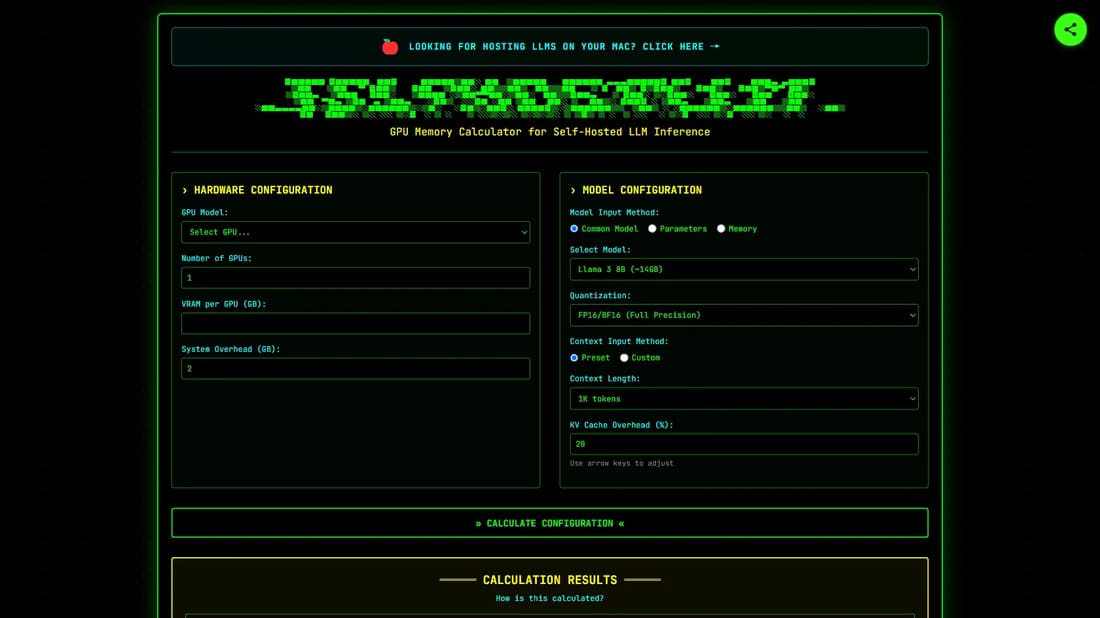
SelfHostLLMは、セルフホスト型LLM(大規模言語モデル)推論のために設計されたGPUメモリ計算ツールです。Llama、Qwen、DeepSeek、Mistralなどの様々なLLMにおいて、GPUメモリ要件と最大同時リクエスト数を計算するのに役立ちます。このツールは異なる量子化レベルとコンテキスト長をサポートしており、AIインフラの効率的な計画を可能にします。モデルメモリ、リクエストごとのKVキャッシュ、推論に利用可能なメモリの詳細な計算を提供し、GPUメモリ帯域幅とモデルサイズ効率に基づいた性能推定も行います。
使い方 SelfHostLLM?
SelfHostLLMを使用するには、GPUモデルを選択し、GPUの数を指定し、システムオーバーヘッドを入力します。使用予定のLLMモデルを選択し、量子化レベルを調整し、コンテキスト長を設定します。計算機はその後、最大同時リクエスト数、利用可能な総VRAM、必要なモデルメモリ、リクエストごとのKVキャッシュを提供します。また、設定に基づいた予想速度と性能評価も推定します。
SelfHostLLM の主な機能
Llama、Qwen、DeepSeek、Mistralなどの幅広いLLMをサポートしており、ユーザーがAIインフラを効率的に計画できるようにします。GPUメモリ要件と最大同時リクエスト数を計算し、モデルメモリ、リクエストごとのKVキャッシュ、推論に利用可能なメモリの詳細な内訳を提供します。GPUメモリ帯域幅とモデルサイズ効率に基づいた性能推定を提供し、ユーザーが設定の予想速度と性能評価を理解するのを助けます。異なる量子化レベルとコンテキスト長をサポートしており、ユーザーがメモリ使用量と性能のためにLLM推論を最適化できるようにします。各計算ステップに対する詳細な説明とともにユーザーフレンドリーなインターフェースを提供し、初心者から経験豊富なユーザーまでアクセス可能にします。
SelfHostLLM の使用例
AI研究者は、異なるLLMを実行するためのハードウェア要件を推定するためにSelfHostLLMを使用でき、実験と展開を効率的に計画するのに役立ちます。AIアプリケーションに取り組む開発者は、異なるGPU構成とモデルサイズの性能影響を理解するためにこのツールを活用し、速度とコストのためにアプリケーションを最適化できます。AIインフラを展開する責任があるITプロフェッショナルは、SelfHostLLMを使用してハードウェアの購入と構成を計画し、意図したLLMワークロードの要件を満たすようにできます。AIと機械学習を教える教育者は、大規模言語モデルを実行する際のハードウェア考慮事項を説明するための実用的な例としてこのツールを使用できます。AIを探求しているスタートアップや中小企業は、LLMを製品やサービスに統合するためのコストとハードウェア要件を推定するためにSelfHostLLMを使用できます。
SelfHostLLM よくある質問
最も影響を受ける職業
AI研究者
機械学習エンジニア
データサイエンティスト
ITプロフェッショナル
開発者
教育者
スタートアップ創設者
中小企業オーナー
テックエンスージアスト
学生
SelfHostLLM のタグ
SelfHostLLM の代替品