SelfHostLLM
为自托管大型语言模型推理计算GPU内存需求。
SelfHostLLM是一款专为自托管大型语言模型(LLM)推理设计的GPU内存计算器。它帮助用户计算包括Llama、Qwen、DeepSeek和Mistral在内的多种LLM的GPU内存需求和最大并发请求数。该工具支持不同的量化级别和上下文长度,使得AI基础设施的规划更加高效。它提供了模型内存、每个请求的KV缓存以及可用于推理的剩余内存的详细计算,同时基于GPU内存带宽和模型大小效率提供了性能预估。
免费
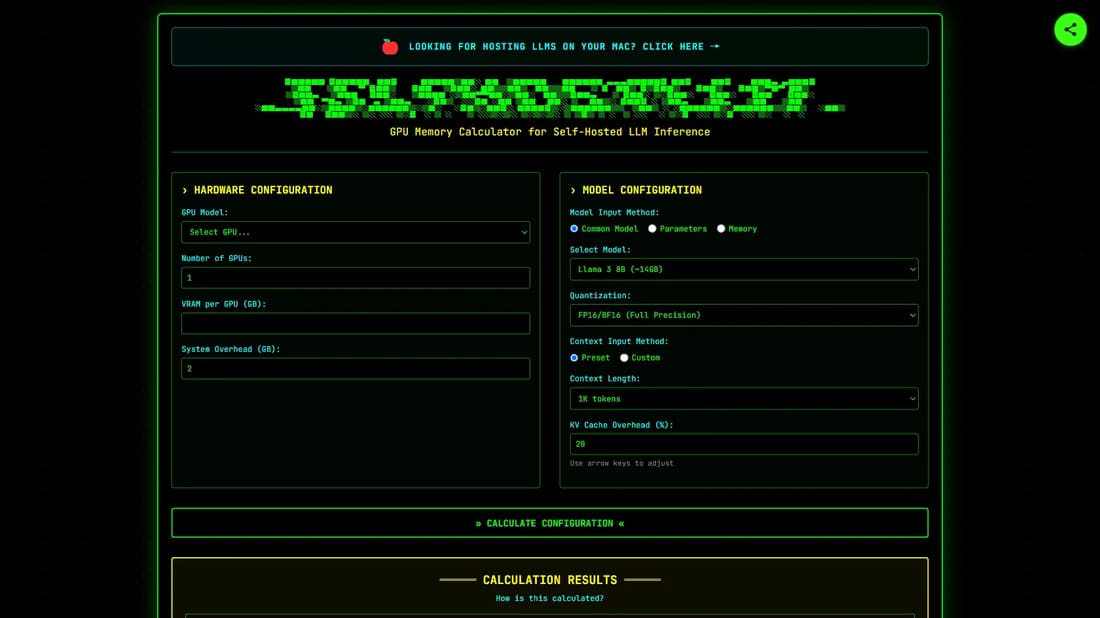
如何使用 SelfHostLLM?
使用SelfHostLLM时,首先选择您的GPU型号,指定GPU数量,并输入系统开销。然后选择您计划使用的LLM模型,调整量化级别,并设置上下文长度。计算器随后将提供最大并发请求数、总可用VRAM、所需模型内存以及每个请求的KV缓存。它还会根据您的配置预估预期速度和性能评级。
SelfHostLLM 的核心功能
SelfHostLLM 的使用场景
SelfHostLLM 的常见问题
最受影响的职业
AI研究员
机器学习工程师
数据科学家
IT专业人员
开发者
教育工作者
初创公司创始人
小企业主
技术爱好者
学生


