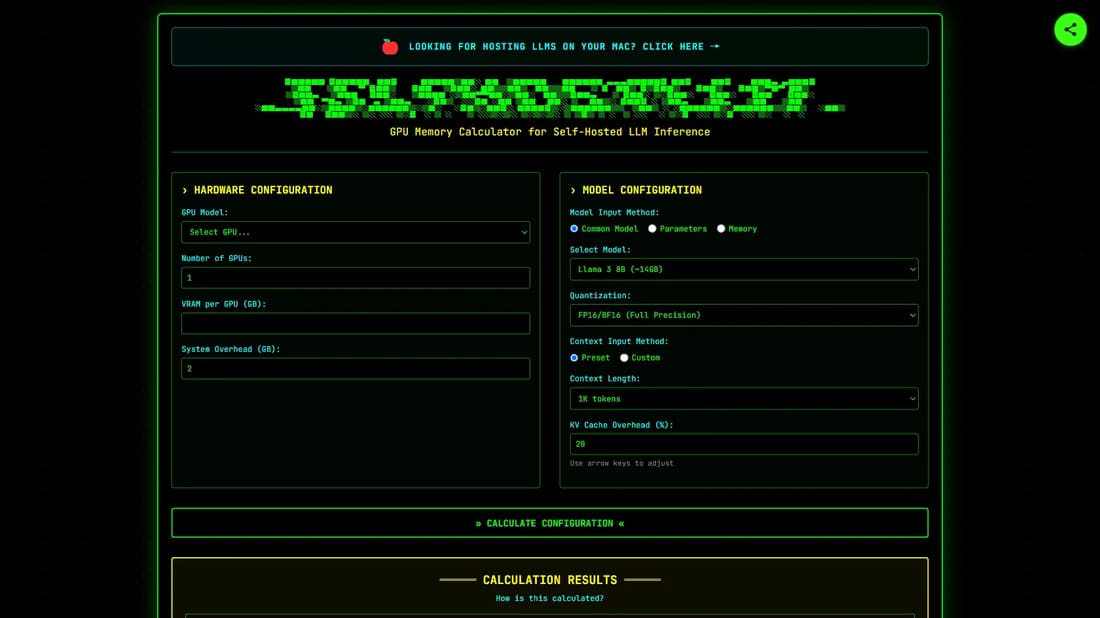
SelfHostLLM은 자체 호스팅 LLM(대형 언어 모델) 추론을 위해 설계된 GPU 메모리 계산기입니다. 이 도구는 Llama, Qwen, DeepSeek, Mistral 등 다양한 LLM에 대한 GPU 메모리 요구 사항과 최대 동시 요청 수를 계산하는 데 도움을 줍니다. 다양한 양자화 수준과 컨텍스트 길이를 지원하여 AI 인프라 계획을 효율적으로 수립할 수 있습니다. 모델 메모리, 요청당 KV 캐시, 추론을 위한 사용 가능한 메모리에 대한 상세한 계산을 제공하며, GPU 메모리 대역폭과 모델 크기 효율성에 기반한 성능 추정도 포함합니다.
무료
사용 방법 SelfHostLLM?
SelfHostLLM을 사용하려면 GPU 모델을 선택하고, GPU 수를 지정하며, 시스템 오버헤드를 입력하세요. 사용할 LLM 모델을 선택하고, 양자화 수준을 조정하며, 컨텍스트 길이를 설정하세요. 그러면 계산기는 최대 동시 요청 수, 사용 가능한 총 VRAM, 필요한 모델 메모리, 요청당 KV 캐시를 제공합니다. 또한 설정에 대한 예상 속도와 성능 등급도 추정합니다.
SelfHostLLM 의 주요 기능
Llama, Qwen, DeepSeek, Mistral 등 다양한 LLM을 지원하여 사용자가 AI 인프라를 효율적으로 계획할 수 있습니다.
GPU 메모리 요구 사항과 최대 동시 요청 수를 계산하며, 모델 메모리, 요청당 KV 캐시, 추론을 위한 사용 가능한 메모리에 대한 상세한 분석을 제공합니다.
GPU 메모리 대역폭과 모델 크기 효율성에 기반한 성능 추정을 제공하여 사용자가 설정의 예상 속도와 성능 등급을 이해할 수 있도록 돕습니다.
다양한 양자화 수준과 컨텍스트 길이를 지원하여 사용자가 메모리 사용량과 성능을 위해 LLM 추론을 최적화할 수 있습니다.
각 계산 단계에 대한 상세한 설명과 함께 사용자 친화적인 인터페이스를 제공하여 초보자와 경험자 모두가 쉽게 접근할 수 있습니다.
SelfHostLLM 의 사용 사례
AI 연구자들은 SelfHostLLM을 사용하여 다양한 LLM을 실행하기 위한 하드웨어 요구 사항을 추정할 수 있으며, 이를 통해 실험과 배포를 효율적으로 계획할 수 있습니다.
AI 애플리케이션 개발자들은 이 도구를 활용하여 다양한 GPU 구성과 모델 크기의 성능 영향을 이해하고, 애플리케이션을 속도와 비용 면에서 최적화할 수 있습니다.
AI 인프라 배포를 담당하는 IT 전문가들은 SelfHostLLM을 사용하여 하드웨어 구매와 구성을 계획할 수 있으며, 의도한 LLM 작업 부하의 요구 사항을 충족시키도록 할 수 있습니다.
AI 및 머신 러닝을 가르치는 교육자들은 이 도구를 실용적인 예시로 사용하여 대형 언어 모델 실행에 관련된 하드웨어 고려 사항을 설명할 수 있습니다.
AI를 탐구하는 스타트업과 소규모 기업들은 SelfHostLLM을 사용하여 제품이나 서비스에 LLM을 통합하기 위한 비용과 하드웨어 요구 사항을 추정할 수 있습니다.